Introduction
The International Classification of Diseases (ICD) is used to code the patient pathway in hospitals by doctors. Today the use of machine learning is a real opportunity to facilitate the codification of patient pathways. The discipline of machine learning that is used in this area is Natural Language Processing (NLP). NLP helps us infer data from raw text. We will present in this document the use of several NLP models with multi-label classification techniques.

Objectives
Our goal is to extract ICD-10 codes from medical analysis documents in french. We will need a coherent dataset in French and apply a learning model with NLP to it with multi-label classification techniques. Also when dealing with medical data, we cannot lose sight of the protection of privacy. We must therefore evolve the learning algorithms so that they integrate the protection of privacy by exploiting methods like pytorch-dp.
Problematics
We have to face several issues.
We have to deal with human error, input documents may contain errors and misspellings. Our model must be able to handle them.
Our objective being also to process data in French, we have to face the lack of consistent data sets in French.
State of the art
The state of the art of CIM-10 code extraction is led by the CLEF e-heath challenge.
CLEF eHealth is a competition in the medical and biomedical field. The goal is to provide researchers with data sets, frameworks for evaluation, and events on which to perform a number of tasks.
CLEF eHealth was created in 2012 as a workshop for preparing an evaluation laboratory and since 2013, it has been carrying out these annual evaluation campaigns in the following areas:
- Information extraction (IE): IE mono- and multilingual, named entity recognition (NER), text classification, acronym standardization, filling in of forms, etc.
- Information management: eHealth data visualization, medical report management, etc.
- Information search (IR) : Mono- and multilingual IR, IR per session.
Some acronyms:
- NER: Named Entity Recognition
- IE: Information extraction
- IR: Information Retrieval
- CLIR: Cross Language Information Retrieval

Organisation
We organized ourselves into a single team of two people. The student Patrice GADEGBE and his supervisor Mr. Jean-François COUCHOT.
We have set up a technological watch system to be up to date on the state of the art of multi-label classification and the translation of large datasets from English to French in order to overcome the lack of data in french.
We have also planned weekly meetings in order to follow the progress of the work together and to be at the same level of information.
Sharing of documents and codes is done using Google Drive and google colaboratory.
In view of the lack of resources on our personal machines and the limitations on google colaboratory, the UFC has offered us access to a much more efficient learning server.
Technical work
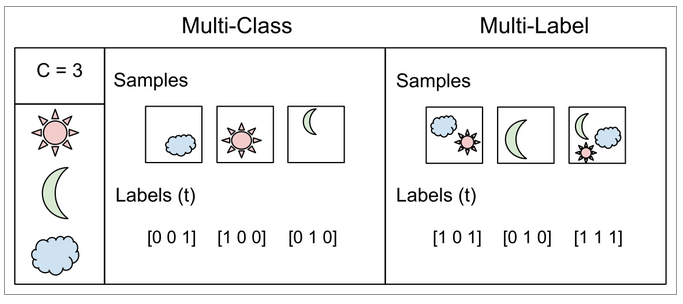
According to wikipedia; In machine learning, multi-label classification and the strongly related problem of multi-output classification are variants of the classification problem where multiple labels may be assigned to each instance. Multi-label classification is a generalization of multiclass classification, which is the single-label problem of categorizing instances into precisely one of more than two classes; in the multi-label problem there is no constraint on how many of the classes the instance can be assigned to. Formally, multi-label classification is the problem of finding a model that maps inputs x to binary vectors y (assigning a value of 0 or 1 for each element (label) in y).
State of the Art of NLP & MultiLabel Classification
The main Pre-trained language representation model BERT (Bidirectional Encoder Representations from Transformers) is the state of the art now with GPT-2. But in our work, we will focus on BERT.
One of the state of the art of the multi-label classification is Fine-tune a DistilBERT Model for Multi Label Classification task of Dhaval Taunk one huggingface.co. We used this work to set up our different machine learning models.
Typically we can subdivide the script code into five parts:
- Data processing
- Training model definition
- Train the model on data
- Evaluate the results
- Save the trained Model
We exploit some published solutions from CLEF e-health specialy the work of Saadullah Amin, Gunter Neumann, Katherine Duneld, Anna Vechkaeva, Kathryn Annette Chapman, and Morgan Kelly Wixted. Mlt-dfki at clef ehealth 2019 : Multi-label classication of icd-10 codes with bert. In CLEF (Working Notes), 2019. We extract their dataset which is the public dataset of a E-clef research work Multi-label Classification of ICD-10 Codes with BERT which is veterinary data.
We use first at all this dataset on a basic multi label classification model based on DistillBert.
Dataset
The first dataset we used is theSentiment analysis dataset in english (Toxic Comment Classification Challenge, Kaggle). Another one is the Veterinary dataset from CLEF that we talked about previously.
We find tooa dataset of Medical Transcriptions from Kaggle that are a dataset scrapped from mtsamples.com.
To use french dataset we use various tools to translate previous datasets. For that we develop and improve our own tool in python using google translate library from pip.
The much efficient tool is an online tool for translating xlsx files: onlinedoctranslator.com.
Model
Bert
Bert is a transformers model pretrained on a large corpus of English data in a self-supervised fashion.
DistilBert
DistillBert is a transformers model, smaller and faster than BERT, which was pretrained on the same corpus in a self-supervised fashion, using the BERT base model as a teacher.
FlauBert
FlauBert is a French BERT trained on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research)
BioBert
BioBert is a biomedical language representation model designed for biomedical text mining tasks
Result analysis
Metrics
We use different metrics to analyse results.
- The Hamming loss is the fraction of labels that are incorrectly predicted.
- Hamming Score/Accuracy: In multilabel classification, this function computes subset accuracy: the set of labels predicted for a sample must exactly match the corresponding set of labels in y_true.
Results
Evolution of loss during epochs of machine learning
| flaubert | bert | distillbert | biobert | |
| 1 | 0,061997246 | 0,03262284398 | 0,1328218579 | 0,04961910844 |
| 2 | 0,1131198779 | 0,1224147081 | 0,05199191719 | 0,03348812461 |
| 3 | 0,06612545252 | 0,05581932142 | 0,1493186653 | 0,04463692009 |
| 4 | 0,09496162832 | 0,04219470173 | 0,02464877628 | 0,03658524901 |
| 5 | 0,08820609748 | 0,01356078405 | 0,04097211361 | 0,009046277963 |
| 6 | 0,09405811876 | 0,01345378626 | 0,03039897792 | 0,01499941386 |
| 7 | 0,08152702451 | 0,07063256949 | 0,02583858371 | 0,05115489289 |
| 8 | 0,07548492402 | 0,01199510228 | 0,06282456964 | 0,01113128848 |
| 9 | 0,04666303471 | 0,00149806554 | 0,03883285075 | 0,02312276699 |

Final results of the learning models
| flaubert | bert | distillbert | biobert | |
| accuracy | 0,477 | 0,6485 | 0,6435 | 0,727 |
| loss | 0,0595 | 0,038 | 0,0392 | 0,0289 |

Conclusion
ICD-10 code extraction using NLP is a real challenge. The previous work of CLEF researchers and our contribution confirms us in the idea of the full accomplishment of this project. The lack of corpus in French is a challenge that can be overcome with good partners such as French hospitals when we can guarantee the confidentiality of data and the protection of privacy. As a perspective, we want to introduce anonymization in our learning models. But learning on anonymized data typically results in a significant degradation in accuracy. We address this challenge by guiding our anonymization by using the best techniques, our target will be to minimize the impact on the model’s accuracy.
References
[RBZ+19] Aude Robert, Yasmine Baghdadi, Pierre Zweigenbaum, Claire Morgand, Cyril Grouin, Thomas Lavergne, Aurelie Neveol, Anne Fouillet, and G Rey. Developpement et application de methodes de traitement automatique des langues sur les causes medicales de deces pour la sante publique. Bulletin Epidemiologique Hebdomadaire-BEH, 5 :603{609, 2019.
[AND+19] Saadullah Amin, Gunter Neumann, Katherine Duneld, Anna Vechkaeva, Kathryn Annette Chapman, and Morgan Kelly Wixted. Mlt-dfki at clef ehealth 2019 : Multi-label classication of icd-10 codes with bert. In CLEF (Working Notes), 2019.
Aurelie Neveol, Aude Robert, Francesco Grippo, Claire Morgand,Chiara Orsi,Laszlo Pelikan , Lionel Ramadier, Gregoire Rey, and Pierre Zweigenbaum CLEF eHealth 2018 Multilingual Information Extraction task overview: ICD10 coding of death certificates in French, Hungarian and Italian